
Beyond the Basics: Advanced Prompting Techniques for LLMs
Navigating the rapidly evolving landscape of LLM prompting – a peek into the future of software development.

There's a treasure trove of fantastic blogs and videos out there with all kinds of guides to interacting with LLMs, mostly featuring our favorite, ChatGPT. But in this post, we're going to venture into a different territory – programming LLMs to handle a variety of complex tasks. Prompting is a part of it and absolutely necessary but it’s also only one piece of the puzzle.
Getting Creative with Single Prompts
A few simple techniques go a long way when you're starting out. You might already know some of these, but you'll be amazed at how even simple changes will up your game when chatting with ChatGPT and its LLM brothers and sisters.
The Devil is in the Details: One of the most important things to remember is that the more detail the better the response. Why? Because LLMs generate responses based on the highest probable tokens that follow the given context - be it your initial prompt or the whole chat history. There's a massive gap between “Rewrite this piece of text” and “Rewrite this piece of text. Keep it engaging and lively. Make it short. Shy away from marketing jargon and exclamation points.”
Role Playing with the LLM: Another fun and effective way to beef up those responses is to assign a role to your LLM. It could be a copywriter, a data scientist, a university professor, Steve Jobs, or even Yoda. It grounds the LLM and gives it context.
Choice is Good: Asking for multiple responses can make a major difference in output quality. Sometimes the first response isn’t all that great, but when you ask for a few responses, you’re bound to get one that works well, and that lets you pull the best one or combine their outputs. This works especially well for creative tasks, like: “What are 5 different titles we could use for this blog?”
Naturally, you can blend a few or all of these techniques into one big prompt, although it might end up being quite a mouthful (or even a veritable essay). Don’t overdo it. Experiment. More is better, but less is more too.
If you find yourself repeatedly dealing with similar tasks using an LLM, you've almost certainly got a batch of trusty prompts squirreled away to get the job done right. It's downright tedious to be copying and pasting these prompts for each new message, isn't it? So, here's my little hack: I set out a comprehensive task in a prompt and then ask the LLM if we're clear. With this trick up my sleeve, all I need to do is grab a prompt from my collection and hit the ground running.

Better Reasoning Now with One Big Prompt
The techniques I've described above tend to suit creative tasks best, tasks that demand a variety of responses and a collaborative process with a human, thereby benefiting from a certain level of unpredictability in results. However, many tasks need more precision, and that gets us on the hunt for more accuracy and fewer flights of fancy and figments of the LLM’s imagination.
A tremendous amount of research and effort is going into getting these LLMs to "think" more effectively. As it stands, even the most advanced models we have on hand (like GPT-4) still have imperfect reasoning and can go off the rails in a way no human ever would. There's a whole suite of techniques out there aimed at curbing these slip-ups, so let’s take a look at a few of them, starting with the ones that work for a single prompt.
Few-shot prompting
Source: Language Models are Few-Shot Learners
This technique is a classic, and it's wonderfully simple. Basically, it works like this: you give the LLM a few question-answer examples to illustrate precisely what you want. Check out this funny example from the original research paper:

While the idea is simple, the choice of examples is not a no-brainer. There's additional research focused on improving this technique, like Calibrate Before Use: Improving Few-Shot Performance of Language Models, Improving Few-Shot Prompts with Relevant Static Analysis Products, and others.
Chain-of-Thought (CoT)
Sources:
If you actively use LLMs, you have most likely heard the term Chain-of-Thought many times already, as this technique is also simple and has become very popular.
This approach centers on coaxing the LLM to explain its reasoning before giving you its answer. When combined with the few-shot approach we discussed above, this leads to better results in many reasoning areas, such as math, understanding dates and times, planning, and state tracking.

However, to make this technique work, you still need to provide plenty of high-quality samples. The authors of the subsequent paper spruced up this method by replacing the examples with a clever phrase: “Let’s think step by step”. As you can see, it’s a huge improvement in terms of UX because the only thing you have to do now is to add this phrase to your prompt.

Fun story: I gave it a go to create an example in ChatGPT to showcase the merits of this method, but it ended up a bit of a flop. It seems that OpenAI has this reasoning style hardwired, so if you throw simple questions like the ones above at it, you'll instantly receive a well-reasoned response. Nevertheless, I find this technique incredibly useful for more complex tasks, like when I'm asking an LLM to select the best piece of text from a set based on less conventional criteria like "exciting" and "easy to read".
If you're integrating the last technique into your programmed pipeline, you might want to give the 2-prompt approach a shot, as suggested by the authors of the second paper. You invite the LLM to think things out step by step, and then you combine the question and answer to tease out the answer in a more computer-compliant format, like a number:
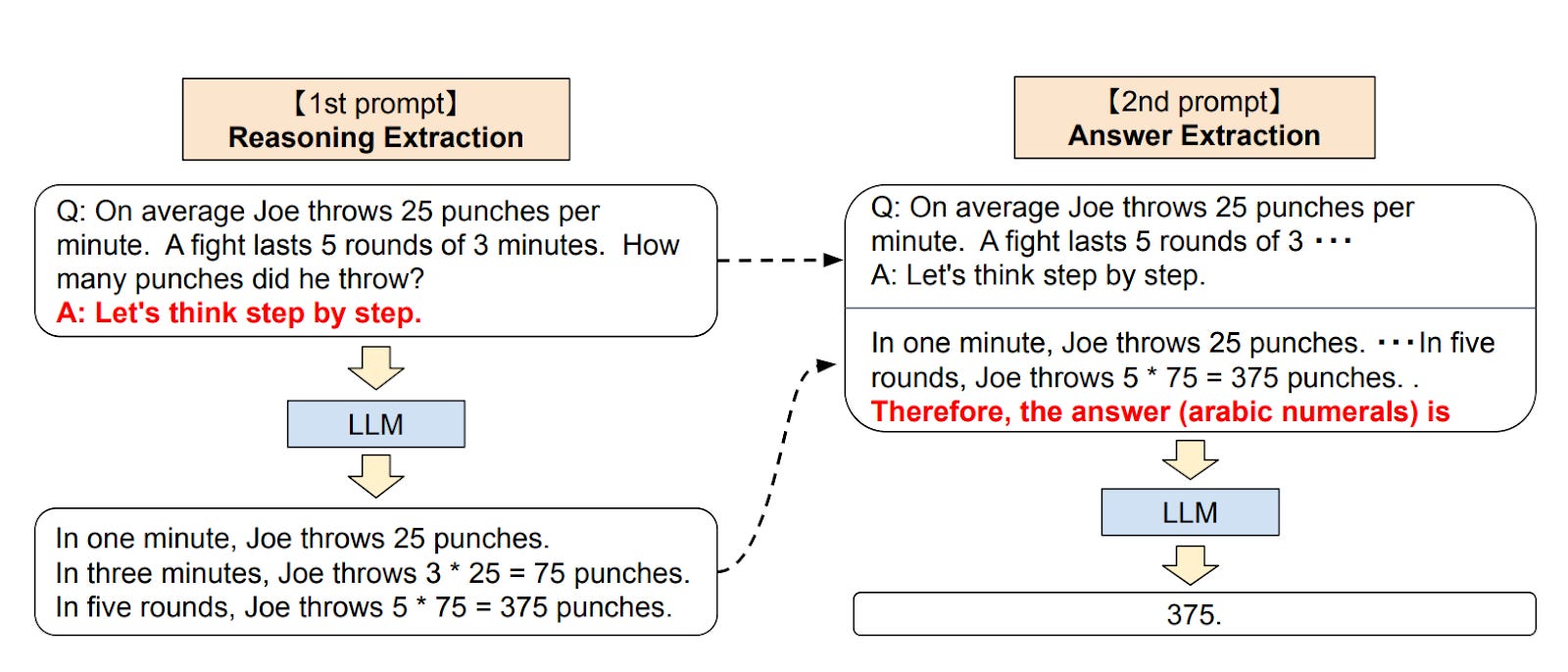
A natural step-up for the Chain-of-Thought is to ask the same question several times and select the answer with the most agreement. Naturally, this only works when the answer is well-defined and easily comparable, like a number or a choice.
Multi-Prompt and Multi-Agent Mastery
As helpful as single-prompt techniques can be, they only take us so far. A natural step up is to use multiple prompts to communicate with one or several LLMs in order to get a final result. Traditional programming comes to the rescue to make these conversations a seamless part of an end-to-end software solution.
This whole area is very new, and there are no established bulletproof tactics here yet. However, in this section, I’ll show two approaches that caught a lot of attention recently: multi-agent setups and marrying LLMs to tree search.

Multi-Agent Setups
The first approach is multiple agents working together on a complex problem. There are a number of great papers on this out there:
Improving Factuality and Reasoning in Language Models through Multiagent Debate
DERA: Enhancing Large Language Model Completions with Dialog-Enabled Resolving Agents
A recurring theme in all these papers is the engagement of multiple LLMs (or agents) in a chat with each other. There can be various ways to structure this dialogue, but in every instance, the authors report a boost in the quality of answers when dealing with tasks that call for reasoning and fact-checking.
The most straightforward technique to grasp is the Multi-Agent Debate (MAD). The idea is as follows: get two or more equivalent agents to address the same question, exchange info, and polish their answers based on insights from their peers. Each round has all agents' answers shared amongst themselves, nudging them to revise their prior responses until they eventually hit a consensus. So essentially, each agent puts in the same effort here.

Progressing further with this concept, we see another technique where different roles are assigned to the agents. This is brought to life in two other research papers we'll discuss.
With the Cross-examination technique, we have two types of LLMs: the Examiner and the Examinee. The Examinee gets posed a question, and the Examiner follows up with additional questions, eventually deciding if the Examinee's response is correct.

Then there's the Dialog-enabled Resolving Agents (DERA) approach, where we distribute slightly different roles. In this case, we have a Decider LLM, whose mission is to complete the task (in this medically-oriented paper, it's making a diagnosis based on patient data), and a Researcher LLM, debating with the Decider LLM to tweak the solution. Their dialog resembles less of an exam and more of a thoughtful exchange between two professionals.

What's so appealing about the multi-agent method is it’s easy to program and highly adaptable to domain-specific applications. The last paper uses it for medical advice, but I could easily see these agents engaging in spirited discussions on a host of subjects, from legal cases and historical contexts to marketing studies and system architecture.
Marrying LLMs to Classical Techniques
Sources:
This is where things take an exciting turn. We now have just one active "thinking" agent, but its thinking mechanism gets augmented by traditional methods from other domains of computer science.
In the Tree of Thought (ToT) scenario, we tie the knot between LLMs and tree search algorithms, such as DFS and BFS. The objective here is to expand the Chain of Thought we previously discussed. Rather than pursuing a single thought thread, we navigate an entire tree. At every stage, we generate a handful of subsequent thoughts for a given state, evaluate each state, and continue. Depending on the specific case, we may explore the whole tree (if it's relatively small) or clip off branches that don't seem too promising.

Assessing the "promise" of a branch (or, in other terms, calculating the score function) is as simple as soliciting an LLM's opinion. The paper lists a few examples of applying this technique to a host of truly challenging reasoning tasks, which essentially boil down to asking an LLM something like, "Please rate the likelihood of success in task [N] from state [X] as possible/impossible/success".
The authors of the Reasoning via Planning (RAP) method took things to a new level by fusing LLMs with Reinforcement Learning. Here, we use Monte-Carlo Tree Search to rapidly iterate through the tree of possibilities. RAP is unique in a couple of major ways:
There's a world model embedded within a second LLM.
The scoring function isn't a static heuristic; instead, we explore routes individually through simulation (hence the need for a world model), reach a terminal state on each path, and propagate the reward back to the top of the tree to refresh the node scores.
So, rather than having just an LLM to assess a state, we have an external state (world) that we can explore in any direction, along with an entire tree of success likelihood scores. Sounds like quite the programming challenge, doesn't it?
Another example of coupling a solitary agent with classic algorithms is shared in my previous post. There, I use a multiple-elimination tournament schema (where everyone plays X games against various opponents, and the winner is simply the one with the highest score). An LLM agent is used as a comparison function, which takes two news items and decides which one is more thrilling. Clearly, one could implement any tournament schema in the same way, depending on the task at hand.
The Big Finish
As you can probably tell, the art of prompting and effectively utilizing LLMs is still in its early days but growing face. Researchers of all stripes are figuring out how to work with these models in new and better ways. While many people out there worry about the limitations or problems of these models, engineers are doing what they do best and solving those problems by working within their limitations. They’re expanding the limitations and making responses more reliable with these powerful new techniques.
That said, most of the strategies we've just walked through are hot off the press, and that means the majority don't yet have sturdy, ready-for-production implementations. That’s all right. They’re still worth learning because you might be the one to get them to production ready through building on their work with your own work.
We’re just beginning to see what's possible with these amazing machines, and we’re just getting started. We’ve got a massive wealth of successful strategies to draw from across the entire history of computer science, and they’re just waiting to be reimagined in ways that augment and enhance LLMS. That's just the tip of the iceberg. I haven't even touched on the studies that involve fine-tuning agents – that's another vast field that's currently out of reach for hobbyists and everyday developers, but I'm certain it will find its way into all our hands in the coming years, maybe even faster.
This is a brand new epoch in software development. It’s exciting and new and it’s made it fun to program again. So get in there and start experimenting. Tell me which of these "wizard's tricks" worked well for you, and find your own too. I certainly haven’t discovered all of them, but they’re out there, just waiting for you to discover them.